Global Identifier
Identifier generation in applications represents a fundamental business requirement. Whether creating purchase orders, users, or any other business entity, each object requires a unique and traceable identifier.

Identifier generation in applications represents a fundamental business requirement. Whether creating purchase orders, users, or any other business entity, each object requires a unique and traceable identifier. This requirement becomes critical when the application begins to scale horizontally (instance multiplication, microservices, etc.).
In conventional applications, auto-incremented identifiers or UUIDs are commonly employed. However, these methods present limitations:
- Incremental identifiers are highly predictable (which may enable, for example, estimation of total order volumes or access to unauthorized resources).
- UUIDs, while marginally more secure, may prove excessively long, insufficiently optimized for certain databases, or lacking business structure.
A more structured and secure approach thus becomes necessary to generate robust, non-predictable identifiers compatible with distributed architecture.
Limitations of Conventional Approaches
Auto-Incrementation
- Highly predictable: these identifiers follow strict sequential ordering, rendering them easily guessable. An attacker may thus estimate data volumes (order quantities, user counts, etc.), or attempt unauthorized access through simple incrementation.
UUID (notably UUIDv4)
- Elevated storage requirements: a UUIDv4 occupies 16 bytes, compared to 4 bytes for an auto-incremented integer (INT). This overhead impacts:
- database performance (indexing, sorting, searching)
- application-side memory utilization, particularly at scale
- Poor readability and manipulation difficulties:
- UUIDs are lengthy, lacking readable structure and difficult for human interpretation.
- they complicate debugging, interface display, or clean URL construction.
- they convey no business information (entity type, creation date, tenant, etc.).
- Theoretical collision risk:
- while rare, collisions remain possible with deficient randomness sources.
- despite vast identifier space (128 bits → 3.4 × 10³⁸ possibilities), very high-volume applications may reach thresholds where these risks become tangible.
GID Presentation
Definition
A Global ID (GID) constitutes a unique representation of an entity within an application. It enables reliable and traceable identification of any business object (user, order, document, etc.), while accounting for tenant context (for example, an organization or client in a multi-tenant application).
Note: a tenant represents an organization or client in a multi-tenant application (i.e., an application utilized by multiple organizations).
Objective and Justification
In this article, we will work with a 24-byte GID. This format is non-standard: most technologies utilize 16 bytes, as defined by standards ISO/IEC 11578:1996, ITU-T Rec. X.667, and RFC 4122 (UUID specification).
We choose a 24-byte (192-bit) GID to address specific requirements:
- guaranteeing reinforced global uniqueness,
- directly incorporating business information (tenant, entity type, timestamp, etc.) within the identifier structure.
- Optimizing for multi-tenancy: avoiding costly joins to identify an entity’s tenant
Regarding performance impact: while 24 bytes exceed standard UUID size (16 bytes), the integrated business information enables avoiding numerous SQL joins, substantially offsetting this overhead. Additionally, indexing remains efficient thanks to the predictable structure.
GID Anatomy (Binary Explanation)
Fundamental Concepts
- Bit: the smallest data unit, representing a binary value (0 or 1).
- Byte: a grouping of 8 bits, sufficient for representing a character or complete data element.
By analogy:
- a bit resembles an elementary letter
- a byte represents the smallest “word” the computer can directly manipulate.
Therefore:
- 2 bytes = 16 bits (2 × 8)
- 8 bytes = 64 bits (8 × 8)
- 24 bytes = 192 bits (24 × 8)
General formula:
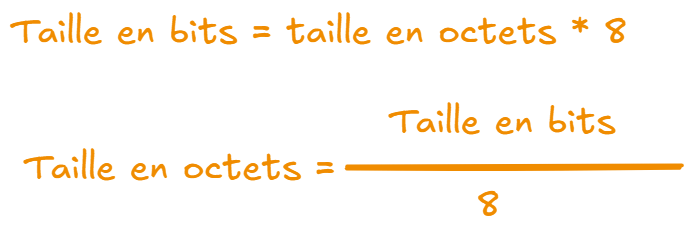
Practical Implementation
We will implement a 24-byte GID with Go, in a multi-tenant system. Each identifier block receives precise allocation to constitute the 24 bytes
| Bytes | Content | Size |
|---|---|---|
| 0-7 | Tenant ID | 8 bytes (64 bits) |
| 8-9 | Entity Type | 2 bytes (16 bits) |
| 10-17 | Timestamp | 8 bytes (64 bits) |
| 18-23 | Random | 6 bytes (48 bits) |
Thus, the GID contains both business information (tenant, type), a timestamp for traceability, and random data guaranteeing global uniqueness.
1. Variable Declaration
package gid
import (
"crypto/rand"
"encoding/binary"
"encoding/hex"
"fmt"
"strings"
"time"
)
const (
GIDSize = 24 // 192 bits total
)
type (
GID [GIDSize]byte // GID = 24-byte array
TenantID [8]byte // Tenant on 8 bytes
)2. GID Initialization
package gid
func NewGID(tenantID TenantID, entityType uint16) {
var id GID // initialize a 24-byte array for our GID
}3. Block Separation and Construction
package gid
func NewGID(tenantID TenantID, entityType uint16) (GID, error) {
var id GID
// 1. Tenant ID (bytes 0 to 7)
// Copy the 8 bytes from tenantID into the first 8 bytes of id
copy(id[0:8], tenantID[:])
// 2. Entity Type (bytes 8 to 9)
// - entityType is a uint16 (16 bits = 2 bytes)
// - Encode it as Big Endian bytes and write it to id[8] and id[9]
binary.BigEndian.PutUint16(id[8:10], entityType)
// 3. Timestamp (bytes 10 to 17)
// - Retrieve the current timestamp in milliseconds
// - Convert it to uint64 (64 bits = 8 bytes)
// - Write these 8 bytes to id[10] through id[17]
now := time.Now().UnixMilli()
binary.BigEndian.PutUint64(id[10:18], uint64(now))
// 4. Random Data (bytes 18 to 23)
// - These 6 bytes serve to guarantee global GID uniqueness
// - Fill them with random bytes
_, err := rand.Read(id[18:24])
if err != nil {
return Nil, fmt.Errorf("failed to generate random bytes: %v", err)
}
return id, nil
}GID Advantages
- Native traceability: integrated timestamp for auditing and debugging
- Context-aware: tenant and entity type directly accessible
- Performance: avoids joins to identify context
- Security: non-predictable thanks to random component
- Flexibility: structured yet extensible format
Conclusion
The code presented here is Go-specific, but the GID concept can be transposed to any programming language.
The primary objective is to visualize how to represent a Global Identifier (GID) informatively, by grouping concrete business data (tenant, entity type, timestamp) while guaranteeing:
- global uniqueness,
- and predictability resistance.
Thus, the GID enables creating identifiers that are simultaneously robust, traceable, and business-useful, while remaining optimized for distributed or multi-tenant architecture.