La génération d’identifiants dans une application est un besoin métier très courant. Que ce soit pour créer des bons de commande, des utilisateurs ou toute autre entité métier, chaque objet a besoin d’un identifiant unique et traçable. Ce besoin devient crucial lorsque l’application commence à scaler horizontalement (multiplication des instances, microservices, etc.).
Dans une application classique, on utilise souvent des identifiants auto-incrémentés ou des UUID. Cependant, ces méthodes présentent des limites :
- Les identifiants incrémentaux sont hautement prévisibles (ce qui peut permettre, par exemple, d’estimer le nombre total de commandes ou d’accéder à des ressources non autorisées).
- Les UUID, bien qu’un peu plus sûrs, peuvent être trop longs, peu optimisés pour certaines bases de données, ou encore manquer de structure métier.
Une approche plus structurée et sécurisée devient donc nécessaire pour générer des identifiants robustes, non prévisibles et compatibles avec une architecture distribuée.
Les limites d’une approche classique
Auto-incrémentation
- Très prévisible : ces identifiants suivent un ordre strict et séquentiel, ce qui les rend facilement devinables. Un attaquant peut ainsi estimer le volume de données (nombre de commandes, d’utilisateurs, etc.), ou tenter des accès non autorisés par simple incrémentation.
UUID (notamment UUIDv4)
- Poids élevé : un UUIDv4 occupe 16 octets, contre 4 octets pour un entier auto-incrémenté (INT). Ce surcoût impacte :
- les performances de la base de données (indexation, tri, recherche)
- l’utilisation mémoire côté application, surtout à grande échelle
- Peu lisible et difficile à manipuler :
- les UUID sont longs, sans structure lisible et difficiles à interpréter pour un humain.
- ils compliquent le debug, l’affichage dans les interfaces, ou la construction d’URLs propres.
- ils ne portent aucune information métier (type d’entité, date de création, tenant, etc.).
- Risque (théorique) de collision :
- bien que rares, les collisions restent possibles si la source d’aléatoire est défaillante.
- même avec un espace d’identifiants très large (128 bits → 3.4 × 10³⁸ possibilités), une application à très haute volumétrie peut atteindre des seuils où ces risques deviennent réels.
Présentation du GID
Définition
Un Global ID (GID) est une représentation unique d’une entité dans une application. Il permet d’identifier de manière fiable et traçable n’importe quel objet métier (utilisateur, commande, document, etc.), tout en tenant compte du contexte du tenant (par exemple une organisation ou un client dans une application multi-tenant).
NB : un tenant représente une organisation ou un client dans une application multi-tenant (c’est-à-dire une application utilisée par plusieurs organisations).
Objectif et justification
Dans cet article, nous allons manipuler un GID de 24 octets. Ce format n’est pas un standard : la plupart des technologies utilisent plutôt 16 octets, tel que défini par les normes ISO/IEC 11578:1996, ITU-T Rec. X.667 et le RFC 4122 (spécification des UUID).
Nous faisons le choix d’un GID sur 24 octets (192 bits) pour répondre à des besoins spécifiques :
- garantir une unicité globale renforcée,
- inclure directement des informations métier (tenant, type d’entité, timestamp, etc.) dans la structure de l’identifiant.
- Optimiser pour le multi-tenant : éviter les jointures coûteuses pour identifier le tenant d’une entité
Concernant l’impact performance : bien que 24 octets soient plus lourds qu’un UUID standard (16 octets), les informations métier intégrées permettent d’éviter de nombreuses jointures SQL, compensant largement ce surcoût. De plus, l’indexation reste efficace grâce à la structure prévisible.
Anatomie du GID (explication binaire)
Notions de base
- Bit : la plus petite unité de données, représentant une valeur binaire (0 ou 1).
- Octet : un regroupement de 8 bits, suffisant pour représenter un caractère ou un élément de données complet.
En analogie :
- un bit est comme une lettre élémentaire
- un octet est le plus petit “mot” que l’ordinateur peut manipuler directement.
Donc :
- 2 octets = 16 bits (2 × 8)
- 8 octets = 64 bits (8 × 8)
- 24 octets = 192 bits (24 × 8)
Formule générale :
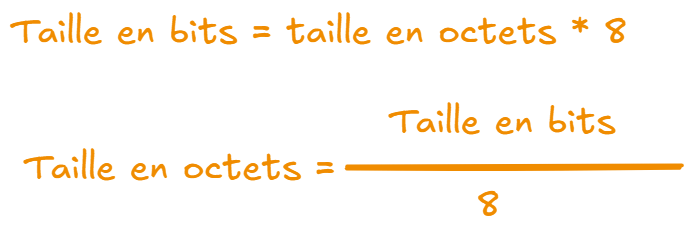
Cas pratique
Nous allons implémenter un GID de 24 octets avec Go, dans un système multi-tenant. Chaque bloc de l’identifiant se voit attribuer une plage précise pour reconstituer les 24 octets
| Octets | Contenu | Taille |
|---|---|---|
| 0-7 | Tenant ID | 8 octets (64 bits) |
| 8-9 | Entity Type | 2 octets (16 bits) |
| 10-17 | Timestamp | 8 octets (64 bits) |
| 18-23 | Random | 6 octets (48 bits) |
Ainsi, le GID contient à la fois des informations métier (tenant, type), un timestamp pour la traçabilité, et des données aléatoires pour garantir l’unicité globale.
1. Déclaration des variables
package gid
import (
"crypto/rand"
"encoding/binary"
"encoding/hex"
"fmt"
"strings"
"time"
)
const (
GIDSize = 24 // 192 bits au total
)
type (
GID [GIDSize]byte // GID = tableau de 24 octets
TenantID [8]byte // Tenant sur 8 octets
)
2. Initialisation du GID
package gid
func NewGID(tenantID TenantID, entityType uint16) {
var id GID // on initialise un tableau de 24 octets pour notre GID
}3. Séparation des blocs et construction
package gid
func NewGID(tenantID TenantID, entityType uint16) (GID, error) {
var id GID
// 1. Tenant ID (octets 0 à 7)
// On copie les 8 octets de tenantID dans les 8 premiers octets de id
copy(id[0:8], tenantID[:])
// 2. Entity Type (octets 8 à 9)
// - entityType est un uint16 (16 bits = 2 octets)
// - On l'encode en bytes Big Endian et on l'écrit dans id[8] et id[9]
binary.BigEndian.PutUint16(id[8:10], entityType)
// 3. Timestamp (octets 10 à 17)
// - On récupère le timestamp actuel en millisecondes
// - On le convertit en uint64 (64 bits = 8 octets)
// - On écrit ces 8 octets dans id[10] à id[17]
now := time.Now().UnixMilli()
binary.BigEndian.PutUint64(id[10:18], uint64(now))
// 4. Données aléatoires (octets 18 à 23)
// - Ces 6 octets servent à garantir l'unicité globale du GID
// - On les remplit avec des bytes aléatoires
_, err := rand.Read(id[18:24])
if err != nil {
return Nil, fmt.Errorf("failed to generate random bytes: %v", err)
}
return id, nil
}Avantages du GID
- Traçabilité native : timestamp intégré pour audit et debug
- Context-aware : tenant et type d’entité directement accessibles
- Performances : évite les jointures pour identifier le contexte
- Sécurité : non-prévisible grâce à la partie aléatoire
- Flexibilité : format structuré mais extensible
Conclusion
Le code présenté ici est spécifique à Go, mais le concept du GID peut être transposé dans n’importe quel langage.
L’objectif principal est de visualiser comment représenter un identifiant global (GID) de manière informative, en regroupant des données métier concrètes (tenant, type d’entité, timestamp) tout en garantissant :
- l’unicité globale,
- et la résistance à la prédictibilité.
Ainsi, le GID permet de créer des identifiants à la fois robustes, traçables et utiles pour le business, tout en restant optimisés pour une architecture distribuée ou multi-tenant.