Du sport à la médecine, en passant par les transports et la sécurité…
Vous êtes-vous déjà demandé comment une caméra de surveillance parvient à reconnaître un visage dans une foule, comment un scanner médical détecte une tumeur dissimulée, ou comment un système suit la trajectoire d’un train avec une précision millimétrique ?
Introduction
Un réseau neuronal convolutionnel (Convolutional Neural Network, ou CNN) est un type d’algorithme d’apprentissage profond supervisé (deep learning) qui confère à un ordinateur une forme de « vision » : il peut ainsi analyser et reconnaître des objets du monde visuel.
Le réseau neuronal convolutionnel (Convolutional Neural Network, CNN), par analogie, se réfère au fonctionnement des réseaux neuronaux biologiques et constitue, par conséquent, une extension du réseau neuronal artificiel (Artificial Neural Network, ANN). Il trouve ses applications principalement dans la reconnaissance et l’analyse d’images.
En s’appuyant sur les principes de l’algèbre linéaire, et plus particulièrement sur la manipulation de matrices, les réseaux neuronaux convolutionnels appliquent des opérations de convolution et de transformation afin de détecter et extraire des motifs pertinents au sein d’une image.
Comment fonctionne le CNN
Le fonctionnement d’un réseau neuronal convolutionnel (Convolutional Neural Network, CNN) repose sur une architecture composée de trois types de couches principales. Ces couches traitent en entrée (input) des données structurées spatialement, telles que des images, des spectrogrammes audio ou des séquences vidéo :
- Couche convolutionnelle (Convolutional layer)
- Couche de sous-échantillonnage ou de pooling (Pooling layer)
- Couche entièrement connectée (Fully connected layer)
Couche convolutionnelle (Convolutional layer)
La couche convolutionnelle est le cœur principal du réseau de neurones, c’est là où la majorité des calculs sont effectués. Son fonctionnement nécessite des composants tels que :
- Des données d’entrée (input data)
- Un filtre (noyau ou kernel)
- Une carte de caractéristiques (feature map)
Fonctionnement :
- Convolution (produit scalaire)
- ReLU (supprime les valeurs négatives)
- Pooling (réduction de taille)
- Répéter ces étapes
- Classification finale
Données d’entrée (Input) : Prenant pour entrée une image de taille 24×24 pixels, qui sera transformée en matrice de pixels 3D correspondant au nombre de pixels respectifs de l’image. Cela veut dire que l’input (la donnée d’entrée) est représenté en hauteur, largeur et profondeur qui correspondent aux caractéristiques RVB de l’image.
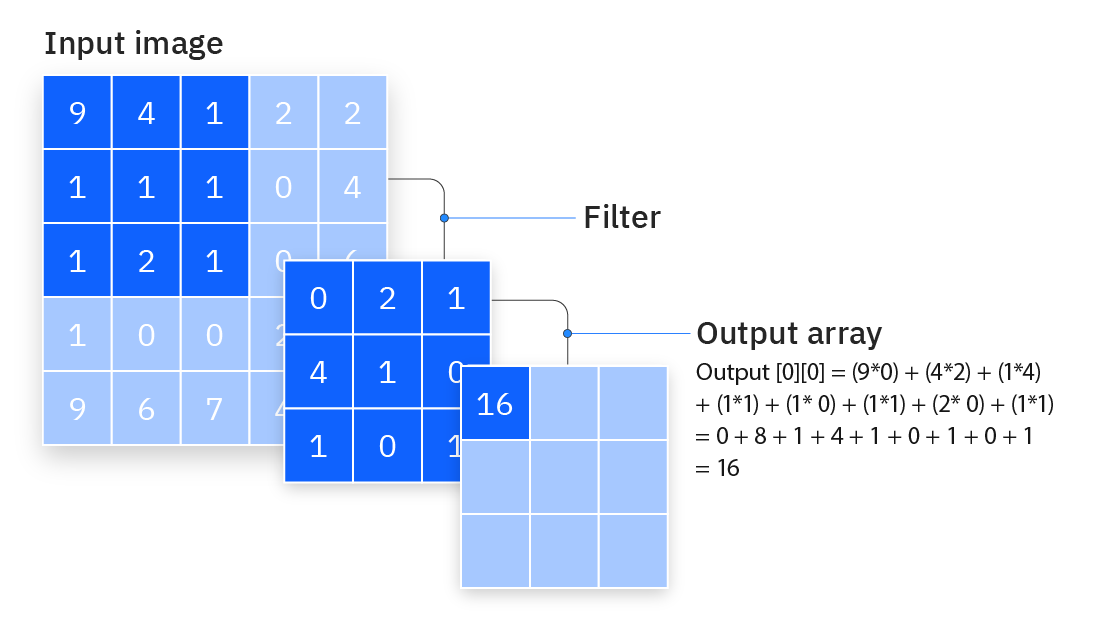
Filtre (noyau) : Le filtre est une matrice de poids qui se déplace sur l’image afin d’en détecter les formes et caractéristiques. Ce processus est connu sous le nom d’opération de convolution.
- Les contours
- Les lignes
- Les textures
- Les formes géométriques
- Des caractéristiques plus complexes dans les couches profondes
Sa taille peut varier, bien que par défaut elle soit de 3×3, il en existe des 5×5, ou 7×7 pixels. Le champ récepteur correspond à la zone de l’image d’entrée qui influence un neurone de sortie.
Le filtre est placé sur une zone de l’image et le produit scalaire est calculé en fonction des pixels d’entrée et du filtre. Cette valeur est alors sauvegardée dans une carte de caractéristiques (feature map). Après cela, le filtre est alors déplacé d’un pas, répétant le processus jusqu’à ce que toute la surface des pixels de l’image soit traitée.
Certains hyper-paramètres du filtre restent fixes durant le processus, par contre les poids sont ajustés afin de maximiser les performances via les opérations de rétropropagation et de descente de gradient. Il existe trois hyper-paramètres qui sont primordiaux dans l’obtention d’un résultat favorable et qui influencent le volume de sortie (output) ; ils doivent être définis bien avant le processus.
-
Number of filters (nombre de filtres) : Affecte la profondeur de la sortie. Par exemple, trois filtres distincts produiraient trois cartes de caractéristiques différentes, créant ainsi une profondeur de trois. Chaque filtre agit comme un détecteur spécialisé (contours, textures, formes) et produit sa propre carte de caractéristiques, ces cartes s’empilent pour former la profondeur de sortie.
-
Stride (pas ou foulée) : Est la distance, ou le nombre de pixels, sur laquelle le noyau se déplace sur la matrice d’entrée. Bien que des valeurs de foulée de deux ou plus soient rares, une foulée plus grande donne une sortie plus petite. Une foulée de 1 signifie que le filtre se déplace pixel par pixel (examen détaillé), tandis qu’une foulée de 2 fait sauter un pixel à chaque déplacement (examen plus rapide, image plus petite).
-
Zero-padding (rembourrage zéro) : Est généralement utilisé lorsque les filtres ne correspondent pas à l’image d’entrée. Cela met à zéro tous les éléments qui se trouvent en dehors de la matrice d’entrée, produisant une sortie plus grande ou de taille égale. Il existe trois types de rembourrage :
- Rembourrage valide : C’est ce qu’on appelle également l’absence de rembourrage. Dans ce cas, la dernière convolution est abandonnée si les dimensions ne s’alignent pas. (Si les pièces du puzzle ne rentrent pas au bord, on les abandonne)
- Rembourrage identique : Ce remplissage garantit que la couche de sortie a la même taille que la couche d’entrée. (On ajoute des pièces vides autour pour que tout rentre parfaitement)
- Rembourrage complet : Ce type de remplissage augmente la taille de la sortie en ajoutant des zéros à la bordure de l’entrée. (On ajoute encore plus de pièces vides pour obtenir une image plus grande)
Après l’opération de convolution, le CNN applique immédiatement la fonction ReLU (Rectified Linear Unit - Unité Linéaire Rectifiée). Cette fonction d’activation agit comme un filtre sélectif qui élimine les signaux faibles (valeurs négatives) pour ne conserver que les activations significatives (valeurs positives).
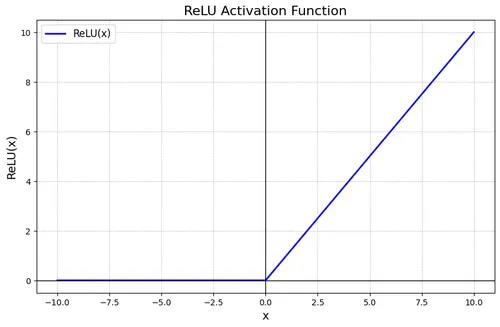
Principe de fonctionnement :
- Valeur positive → conservée telle quelle
- Valeur négative → transformée en zéro
Formule : ReLU(x) = max(0, x)
Exemple pratique :
Carte de caractéristiques avant ReLU : [-2, 5, -1, 8, -3, 4]
Carte de caractéristiques après ReLU : [0, 5, 0, 8, 0, 4]
Impact sur l’apprentissage : L’introduction de cette non-linéarité est cruciale car elle permet au réseau de modéliser des relations complexes entre les caractéristiques. Sans ReLU, le CNN serait limité à des transformations linéaires et ne pourrait pas détecter des motifs sophistiqués comme les relations spatiales entre les éléments d’un visage (distance œil-nez, configuration bouche-joues) ou d’autres subtilités visuelles complexes.
Cette étape transforme donc un simple calcul mathématique en un véritable processus de reconnaissance intelligent.
Couche convolutive supplémentaire
Il est fréquent qu’une hiérarchisation de couches soit appliquée pour analyser progressivement la complexité croissante d’une image. Cette architecture en cascade permet à la structure du CNN de s’adapter intelligemment : les couches ultérieures peuvent exploiter les informations des champs récepteurs des couches précédentes, créant ainsi une véritable hiérarchie de détection.
Principe de la hiérarchie des caractéristiques :
- Couches initiales : Détectent les caractéristiques de bas niveau (contours, lignes, textures simples)
- Couches intermédiaires : Combinent ces éléments pour identifier des formes plus complexes (angles, courbes, motifs géométriques)
- Couches profondes : Reconnaissent des parties d’objets spécifiques (roues, guidons, cadres)
- Couches finales : Assemblent ces parties pour identifier l’objet complet (vélo, voiture, visage)
Exemple concret : Prenons la reconnaissance d’un vélo. Le CNN procède par étapes :
- Détection des cercles et lignes droites
- Identification de formes circulaires (roues potentielles)
- Reconnaissance du guidon et du cadre
- Association finale : “roues + guidon + cadre = vélo”
Cette approche hiérarchique permet au réseau de construire une compréhension progressive de l’image, où chaque couche affine et enrichit l’analyse de la précédente. In fine, la couche convolutionnelle convertit l’image en valeurs numériques structurées, permettant au réseau neuronal d’interpréter et d’extraire les motifs pertinents pour la classification finale.

Couche de sous-échantillonnage ou de pooling (Pooling layer)
Dans cette étape du processus CNN, les informations collectées sont réduites et regroupées afin de diminuer la dimensionnalité des données. Dans le même processus que la couche convolutive, elle applique un filtre qui, à l’inverse de la couche convolutive, n’a pas de poids. Une fonction d’agrégation est appliquée aux valeurs du champ récepteur afin de remplir le tableau de sortie. Cette fonction d’agrégation constitue le paramètre principal configurable qui détermine le type de pooling utilisé.
Objectifs principaux :
- Réduire la taille des données
- Diminuer le nombre de paramètres
- Conserver les caractéristiques importantes
Les deux principaux types de pooling (fonctions d’agrégation) :
1. Max Pooling (Regroupement maximal) :
- Fonction d’agrégation :
f(région) = max(valeurs) - Sélectionne la valeur maximale dans chaque région du champ récepteur
- Conserve les caractéristiques les plus saillantes
- Plus couramment utilisé car il préserve les contours et détails importants
2. Average Pooling (Regroupement moyen) :
- Fonction d’agrégation :
f(région) = moyenne(valeurs) - Calcule la moyenne arithmétique de toutes les valeurs dans le champ récepteur
- Lisse les données en réduisant le bruit
- Moins utilisé mais utile pour certaines applications spécifiques
Visualisation
Région 2×2 organisée comme une matrice :
.png)
Calculs selon le type de pooling :
Max Pooling :
- On regarde toutes les valeurs :
1, 3, 2, 4 - On prend la plus grande :
max(1, 3, 2, 4) = 4 - Résultat : 4
Average Pooling :
- On additionne toutes les valeurs :
1 + 3 + 2 + 4 = 10 - On divise par le nombre de valeurs :
10 ÷ 4 = 2.5 - Résultat : 2.5
Visualisation du processus :
.png)
Le filtre de pooling “regarde” cette région 2×2 et la résume en une seule valeur selon la fonction d’agrégation choisie.
Ces paramètres (type de fonction d’agrégation, taille du filtre, stride) sont configurables avant l’entraînement selon les besoins spécifiques du modèle, permettant d’adapter le comportement du pooling à la tâche de classification visée.
Couche entièrement connectée (Fully connected layer)
Cette couche effectue une classification en fonction des caractéristiques extraites des couches précédentes et de leurs filtres. Elle applique une fonction d’activation (généralement softmax) qui permet de convertir les données en probabilités : chaque classe possible reçoit un score entre 0 et 1, et la somme de toutes les probabilités égale 1.
Exemple :
Pour reconnaître des animaux :
- Chat : 0.7 (70% de probabilité)
- Chien : 0.2 (20% de probabilité)
- Oiseau : 0.1 (10% de probabilité)
- Total : 0.7 + 0.2 + 0.1 = 1.0
La classe avec la plus haute probabilité (ici “Chat” avec 0.7) est la prédiction finale.
Conclusion
Les réseaux neuronaux convolutionnels (CNN) constituent une architecture d’apprentissage profond particulièrement efficace pour le traitement et l’analyse d’images. Leur fonctionnement repose sur trois composants principaux : les couches convolutionnelles qui extraient les caractéristiques, les couches de pooling qui réduisent la dimensionnalité, et les couches entièrement connectées qui effectuent la classification finale.
Architecture et performances
Cette structure hiérarchique permet aux CNN de détecter progressivement des motifs de plus en plus complexes, depuis les contours simples jusqu’aux objets complets. Les hyper-paramètres configurables (nombre de filtres, stride, padding) offrent une flexibilité d’adaptation selon les besoins spécifiques de chaque application.
Applications pratiques
Les CNN trouvent aujourd’hui des applications concrètes dans de nombreux secteurs : diagnostic médical par imagerie, systèmes de surveillance automatisée, contrôle qualité industriel, et véhicules autonomes. Leur capacité à traiter efficacement de grandes quantités de données visuelles en fait un outil incontournable pour ces domaines.
Perspectives techniques
L’optimisation continue des architectures CNN, combinée à l’amélioration des capacités de calcul, permet d’envisager des applications plus complexes et une précision accrue dans les tâches de reconnaissance d’images. La compréhension de ces mécanismes fondamentaux reste essentielle pour développer et implémenter efficacement ces solutions technologiques.